Custom Usage¶
Now we introduce the pipeline to migrate your full-model tuning scripts to a delta tuning one, especial when your model is not in the default configuration list, or you don’t want to use ghte default configuration.
STEP 1: Load the pretrained models¶
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained("facebook/bart-base") # suppose we load BART
STEP 2: Add delta modules¶
We provide two alternatives to add the delta modules.
2.1 Visualize the backbone structure¶
Delta tuning’s core change in the structure of the base model is to decorate (modify) the modules of the base model with small delta modules. We assume we want to treat the feedforward layer of each block as our target modules. Since different PLM name the submodules differently,
We should first know the name of the feedforward layer in the BART model by visualization. ![]() For more about visualization, see Visualization.
For more about visualization, see Visualization.
from bigmodelvis import Visualization
Visualization(model).structure_graph()
Click to view output
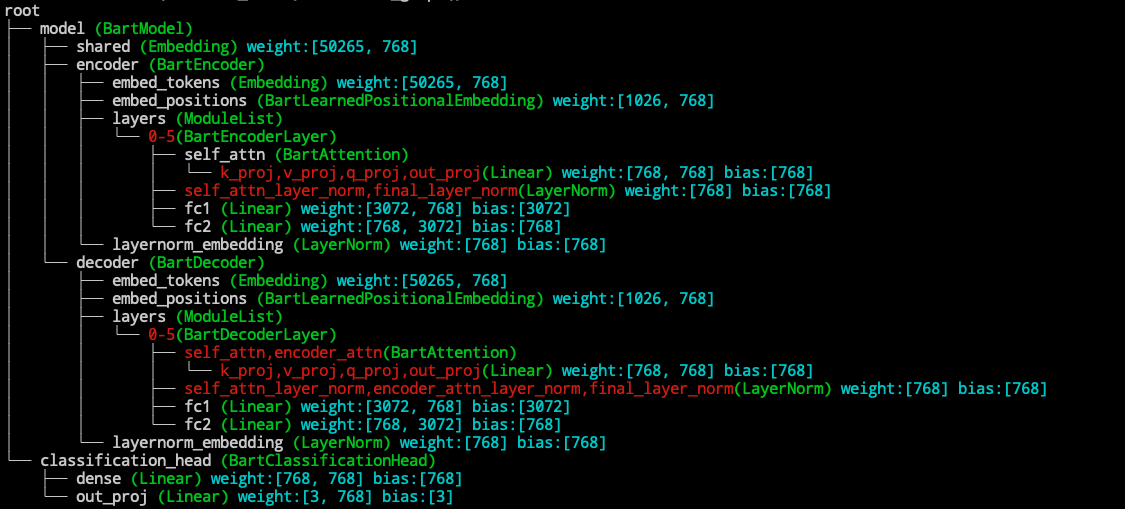
We can see from the structure graph that the feed forward layer in Bart is called model.encoder.layers.$.fc1 and model.encoder.layers.$.fc2, where
$ represent a number from 0-5. Since we want to apply adapter after all the feed forward layers, we specify the modified_modules=['fc2'], which is the common suffix for feed forward layers.
![]() For details about the name based addressing, see Name-based submodule addressing
For details about the name based addressing, see Name-based submodule addressing
Other configurations, such as the bottleneck_dim in Adapter, can be passed as key word arguments.
from opendelta import AdapterModel
delta_model = AdapterModel(backbone_model=model, modified_modules=['fc2'], bottleneck_dim=12)
delta_model.log() # This will visualize the backbone after modification and other information.
Try different positions
OpenDelta provide the flexibility to add delta to various positions on the backbone model. For example, If you want to move the adapter in the above example after the layer norm of the feed forward layer. The code should be changed into
delta_model = AdapterModel(backbone_model=model, modified_modules=['final_layer_norm'], bottleneck_dim=12)
The performance may vary due to positional differences, but there is currently theorectical guarantee that one will outperform the other.
Favored Configurations
Feel confused about the flexibility that OpenDelta brings? The default configuration is the default_modified_modules attributes of each Delta model. Generally, the default configurations are already good enough. If you want squeeze the size of delta models further, you can refer to the following papers.
STEP 3: Freeze parameters¶
So far the backbone model is still fully tunable. To freeze the main part of the backbone model except the trainable parts (usually the delta paramters), use freeze_module method. The syntax of exclude field also obeys the name-based addressing rules.
delta_model.freeze_module(exclude=["deltas", "layernorm_embedding"])
delta_model.log()
Click to view output
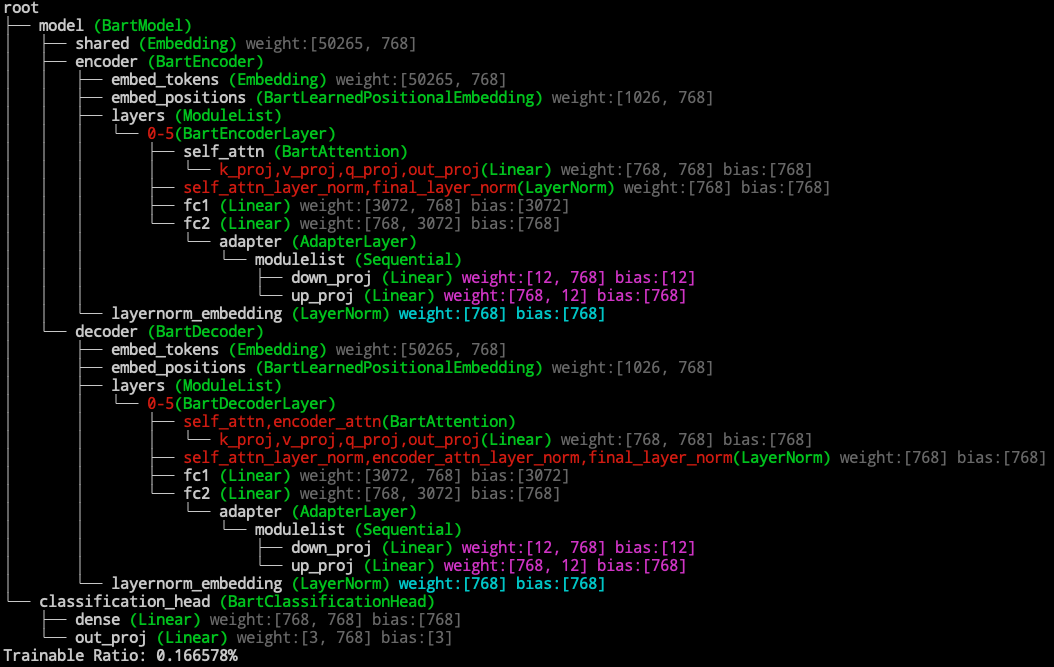
Usually, we want to only save the trainable part, then we should modify the state_dict of the backbone model which original contains all the parameters. Now with set_state_dict=True, the model.state_dict() only contains the trainable parameters.
delta_model.freeze_module(exclude=["deltas", "layernorm_embedding"], set_state_dict=True)
STEP 4: Normal training pipeline¶
The model then can be trained in traditional training scripts. Two things should be noticed:
Note
No need to change the optimizer, since the optimizer will only calculated and store gradient for those parameters with
requires_grad=True, and therequires_gradattribute has been changed during the call to freeze_module method.model.eval()ormodel.train()should be used if we need to enable/disable dropout. Opendelta doesn’t touch those configuration.
STEP 5: Save and load the Delta Model¶
Option1: Use opendelta interface.¶
One option is to use our provided interface. This will save both the configurations of the delta model and the parameters of all trainable parameters.
delta_model.save_finetuned("some_local_path/")
When loading the delta_model, just call the from_finetuned methods. Note that the loaded model is fully trainable. If you want to continue to train it, please use freeze_module again.
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained("facebook/bart-base")
from opendelta import AutoDeltaModel
delta_model = AutoDeltaModel.from_finetuned("some_local_path/", backbone_model=model)
Option2: Use pytorch interface.¶
Another option is to load the model using traditional pytorch ways.
torch.save(model.state_dict(), "some_local_path/pytorch_model.bin")
Then load it into an initialied backbone model with delta model. Remember to use strict=False since now the state_dict contains only the trainable parameters.
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained("facebook/bart-base")
from opendelta import AdapterModel
delta_model = AdapterModel(backbone_model=model, modified_modules=['fc2'], bottleneck_dim=12)
model.load_state_dict(torch.load("some_local_path/pytorch_model.bin"), strict=False)
Option3: Save and upload to DeltaCenter.¶
You can also save the delta model to delta center to share with the community. See instructions.